Set in Java
I.Set 接口
java.util.Set
- Set 接口是 Collection 接口的子接口,用法和 Collection 完全相同
- Set 的某些实现类中的元素是
无序的, 比如HashSet (无指存储和取出的元素顺序不一致) - Set 中元素
不可重复, 值唯一,最多允许一个 null 值
注意事项:
- Set接口中基本都是是 Collection 的方法
- 虽然 Set 集合的元素无序,但是作为集合来说,它肯定有它自己的存储顺序,如果你的顺序恰好和它的存储顺序一致,这代表不了有序
II. Set 的实现类
1. HashSet
java.util.HashSet
- 此类实现 Set 接口,底层数据结构是哈希表(实际上是一个 HashMap 实例)
- 它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变,即
无序 - 此类允许使用 null 元素。
- 线程不安全
- 迭代器 fast-false
package org.lovian.collections.set;
import java.util.HashSet;
/*
* HashSet: store strings and traverse
*
*/
public class HashSetDemo {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<>();
hs.add("hello");
hs.add("world");
hs.add("hello"); // just store one "world" in hashset
// traverse hashset
for(String s : hs){
System.out.println(s);
}
}
}
result
world
hello
我们发现,这里只存在了一个hello,第二个 hello 并没有被存入 hashset 中, 而且结构还没有顺序,这是为什么呢?
HashSet 的本质
HashSet 的底层是一个 HashMap<E, new Object()>。 比如 HashSet 的 add
所以在 HashSet 存储元素的时候,实际上相当于 HashMap 添加一个 Key,源代码如下
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 计算哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 在 HashMap 中有一个哈希表
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 首先先比较对象的哈希值,然后比地址,然后比 equals
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
从源码可以看出,我们可以发现 HashSet 的 Set 方法底层依赖了两个方法: hashCode() 和 equals(),步骤是这样的:
- 首先比哈希值 hashCode
- 如果结果相同,那么比较对象的地址值或者 equals 方法
- 如果不同,那么就直接添加到集合中
所以如果类没有重写这两个方法,那么默认使用的是 Object 的 hashCode() 和 equals(), 一般来说哈希值是不同的,而上个例子中,String 类重写了 hashCode 和 equals, 所以两个 “world” 对象计算得到的值是相同的(实际上在字符串池中,只有一个 “world”)
哈希表结构
在 HashMap 中源代码中我们可以发现存在了一个哈希表 tab[i] ,这个哈希表实际上是一个元素为链表的数组,综合了数组和链表的好处(类似于字典),这个链表更确切的说是一个哈希桶, 里面存储着哈希值相同,但并不相同(equals)的多个对象, 图示如下:

- 这个数组的索引其实就是
哈希值经过计算后的一个值- 如果对象的哈希值不同,那么在这个哈希表中,索引也不同,那么添加一个新的哈希桶,把对象装进去
- 如果对象的哈希值相同,那么通过索引,找到这个哈希桶,比较对象的地址值或者 equals 方法
- 如果对象相同, 那么哈希表会认为这个对象早已经存在在这个哈希桶里,不再添加
- 如果对象不同, 那么这个对象会被添加到这个哈希桶里存储起来
这就是为什么 HashSet 中元素不重复的原因。由图也可知,经过一次哈希值的计算,不同哈希值的对象会被分散到不同的哈希桶,在哈希桶中,每个对象又是通过链表存储,所以,set中元素的顺序并不能得到保证!也是 HashSet 中无序的原因
HashSet 存储自定义对象保证不重复
根据上述解释,在 HashSet 中存储自定义对象,这个自定义对象需要重写 hashCode 方法和 equals 方法
2. LinkedHashSet
java.util.LinkedHashSet:
- HashSet的子类
- 底层结构是
哈希表和双重链表- 哈希表保证元素的唯一性
- 双重链表保证元素
有序: 存储和取出是一致的
- 功能全部继承余父类和实现接口中的方法
package org.lovian.collections.set;
import java.util.LinkedHashSet;
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<String> hs = new LinkedHashSet<>();
hs.add("hello");
hs.add("world");
hs.add("lovian");
hs.add("hello");
hs.add("java");
for(String s : hs){
System.out.println(s);
}
}
}
result:
hello
world
lovian
java
3. TreeSet
java.util.TreeSet
TreeSet是基于TreeMap的NavigableSet实现- 底层结构是
红黑树,(自平衡的二叉树,自平衡是它会自动平衡左右子数的子节点) - TreeSet 中元素
不重复 - 能够按照某种规则对元素排序,即
有序- 自然派序:使用元素的
自然顺序对元素进行排序 - 比较器排序:或者根据创建 set 时提供的
Camparator(显式比较器)进行排序
- 自然派序:使用元素的
- 基本操作(add,remove,contains) 时间开销为
log(n)
package org.lovian.collections.set;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
natureSortTreeSet();
}
public static void natureSortTreeSet(){
// 无参构造,自然排序并且去重
TreeSet<Integer> ts = new TreeSet<>();
// [20,18,34,45,14,21,9,31,40, 40, 2, 2]
ts.add(20);
ts.add(18);
ts.add(34);
ts.add(45);
ts.add(14);
ts.add(21);
ts.add(9);
ts.add(31);
ts.add(40);
ts.add(40);
ts.add(2);
ts.add(2);
// already sorted
for(Integer i : ts){
System.out.println(i);
}
}
}
result:
2
9
14
18
20
21
31
34
40
45
TreeSet 自然排序本质
TreeSet 实际上底层结构是个 TreeMap<E, new Object()>,而 TreeMap 是基于 红黑树(Red-Black tree) 的实现,其键值对的映射是根据 key 的自然顺序进行排序,或者根据显式比较器的顺序进行排序.
我们来看源码,TreeSet 的 add 方法,本质上是 TreepMap 的 put 方法:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key); // 自然排序比较的本质,compareTo方法,是Comparable接口定义的
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
实际上,上个例子中对 Integer 进行排序时说的是自然排序,是因为 Integer 这个类实现了 Camparable 这个接口。而从源码可以看出,真正进行元素之间的比较, 一种方式是用了元素的 compareTo() 方法,这个方法是定义在 Comparable 里的。所以要想重写该方法,就必须先实现 Comparable 接口,这个接口表示的就是自然排序; 另一种方式是用的 Comparator接口的方法 compare()
树结构
TreeSet 的底层,是一个红黑树,也就是一个自平衡二叉树,图示如下:
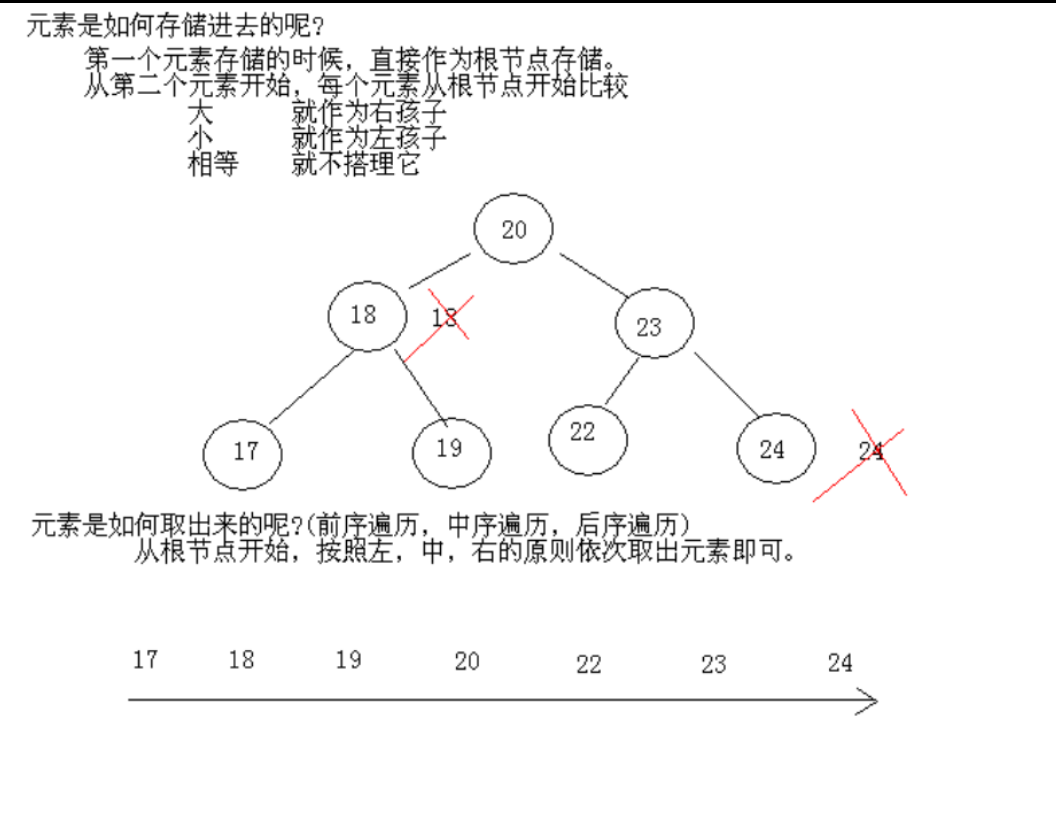
在源代码中,TreeSet 在添加元素时,实际上是往红黑树中添加元素:
- 添加第一个元素时,建立一个根节点,将元素作为根结点存储
- 从第二个元素开始:每个元素从根节点开始比较,
- 大: 如果已经有右孩子了,再根右孩子比,否则作为右孩子存储,
- 小: 作为左孩子存储
- 相等: 则不填加 (这里保证了树中元素的唯一性)
所以在遍历 TreeSet的时候,实际上是遍历红黑树,树的遍历方式有三种:
- 前序遍历(根左右)
- 中序遍历(左根右)
- 后序遍历(左右根)
而要保证按顺序遍历红黑树,使用的是中序遍历
TreeSet存储自定义对象并保证排序和唯一
要保证 TreeSet 中元素的唯一性,是需要比较元素的,那么
- 自然排序:
- 自定义对象就必须要实现自然排序接口
Camparable, 从而重写compareTo方法 compareTo方法, 小于返回 “-1”, 大于返回 “1”, 相等返回 “0”
- 自定义对象就必须要实现自然排序接口
- 比较器排序:
- 定义一个类,比如 MyComparator 实现
Comparator<E>接口,这里是你要比较的对象的类, 比如 Student - 在类中重写
compare方法 - 声明 TreeSet 的时候,往 TreeSet 的构造器中传入你定义的这个比较类的实例(new MyComparator())
- 或者使用 Comparator 的匿名内部类
- 定义一个类,比如 MyComparator 实现
Share this on