数据结构简介
数据结构,是数据的组织方式
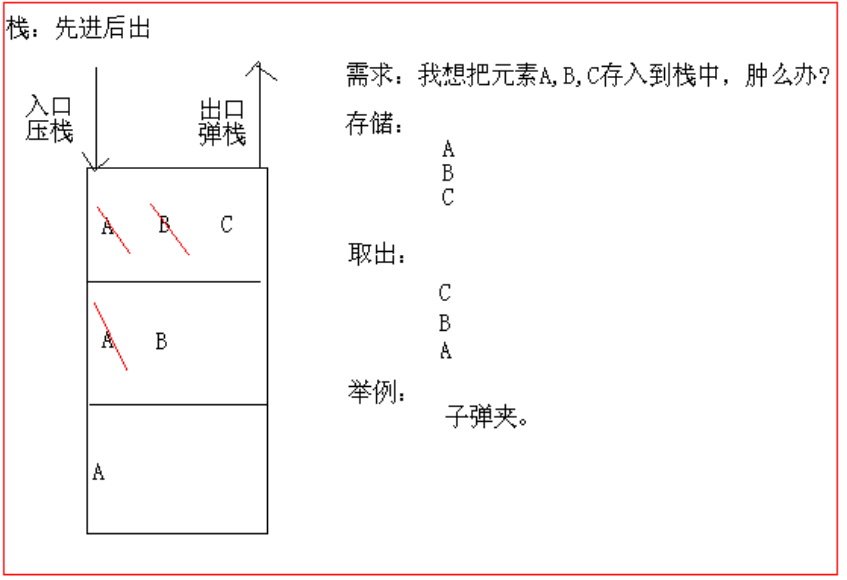
I. 栈 stack
- 特点: 先进后出 FILO first in last out(类似子弹夹)
- 存储: 压栈,将数据压入栈中,最后压进栈的元素在栈的最上层
- 取出: 弹栈,将数据从栈中取出,取出栈的最上层的元素,即最后一个压入栈中的元素
图示如下:
II. 队列
- 特点: 先进先出 FIFO first in first out (类似排队买票)
- 存储:
- 取出:
图示如下:

III. 数组
- 数组:存储同一种类型的多个元素的容器
- 特点:有索引,
查询快,增删慢 - 定义数组:
int[] array = new int[5]int[] array = {1,2,3,4,5}
- 存储:通过索引
array[2] = 1; - 获取:通过索引 array[2]
- 删除:新建数组,把要删除元素之外的所有元素存入新数组,然后返回
图示如下:

IV. 链表
- 由一个链子把多个结点连起来组成的一种结构
- 结点:由数据(数据域) 和地址 (指针域) 组成
- 数据域:保存当前结点的数据
- 指针域:保存下一个结点的内存地址,实际是指向下一结点的指针
- 存储:在插入位置上插入一个结点 N,把插入位置上的原结点记为 M,那么把插入位置的上一个结点的地址域改成指向 N 的地址,N的地址域指向 M 的地址值
- 获取:取出一个元素则要从链表的头 head 开始,然后一个一个找这个元素
- 删除:删除结点 N,记 N 的指针域指向的结点为 M, N 的上一个结点为 P, 那么直接将 P 的指针域改为 M 的地址值
- 特点:
查询慢,增删快
图示如下:
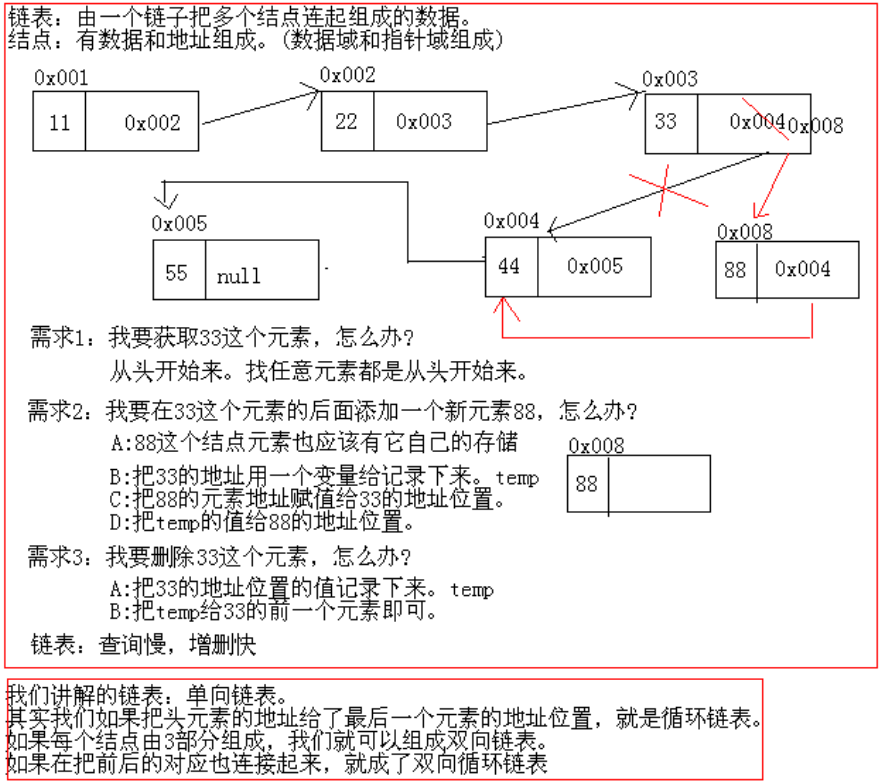
其实上述是个单向链表,还有以下的链表,原理相同
- 循环链表: 链表尾部结点 tail 的指针域指向 链表头部结点 head的地址
- 双向链表: 有两个指针域,一个指针域指向上一个结点的地址,一个指针域指向下一个结点的地址,这样就构成了双向链表
V. 树
见 TreeSet 中解释
VI. 哈希表
见 HashSet 中解释
Share this on